LM Studio 配置指南
LM Studio 是一款图形界面友好的本地大模型运行工具,让你无需命令行也能轻松运行开源 AI 模型。
什么是 LM Studio?
LM Studio 是一款桌面应用程序,专为在本地运行大语言模型设计:
- 图形界面:直观的用户界面,无需命令行知识
- 模型市场:内置模型搜索和下载功能
- 本地服务器:一键启动兼容 OpenAI 的 API 服务
- 跨平台:支持 Windows、macOS、Linux
安装 LM Studio
步骤 1:下载安装包
- 访问 LM Studio 官网
- 点击「Download」
- 选择对应系统的安装包:
- Windows:
.exe安装程序 - macOS:
.dmg安装包 - Linux:
.AppImage文件
- Windows:
步骤 2:安装应用
Windows:
运行下载的 .exe 文件,按提示完成安装
macOS:
打开 .dmg 文件,将 LM Studio 拖入应用程序文件夹
Linux:
chmod +x LM_Studio-*.AppImage
./LM_Studio-*.AppImage
下载和加载模型
步骤 1:搜索模型
- 打开 LM Studio
- 点击左侧的「Search」图标
- 搜索你想要的模型,如:
llama 3.2- Meta 开源模型qwen 2.5- 阿里开源模型mistral- 高效开源模型
步骤 2:下载模型
- 在搜索结果中选择模型
- 选择合适的量化版本(建议):
Q4_K_M:平衡质量和速度Q5_K_M:更好质量,稍慢Q8_0:最高质量,需要更多内存
- 点击「Download」开始下载
步骤 3:加载模型
- 下载完成后,点击左侧的「Chat」图标
- 在顶部的模型选择器中选择已下载的模型
- 等待模型加载完成
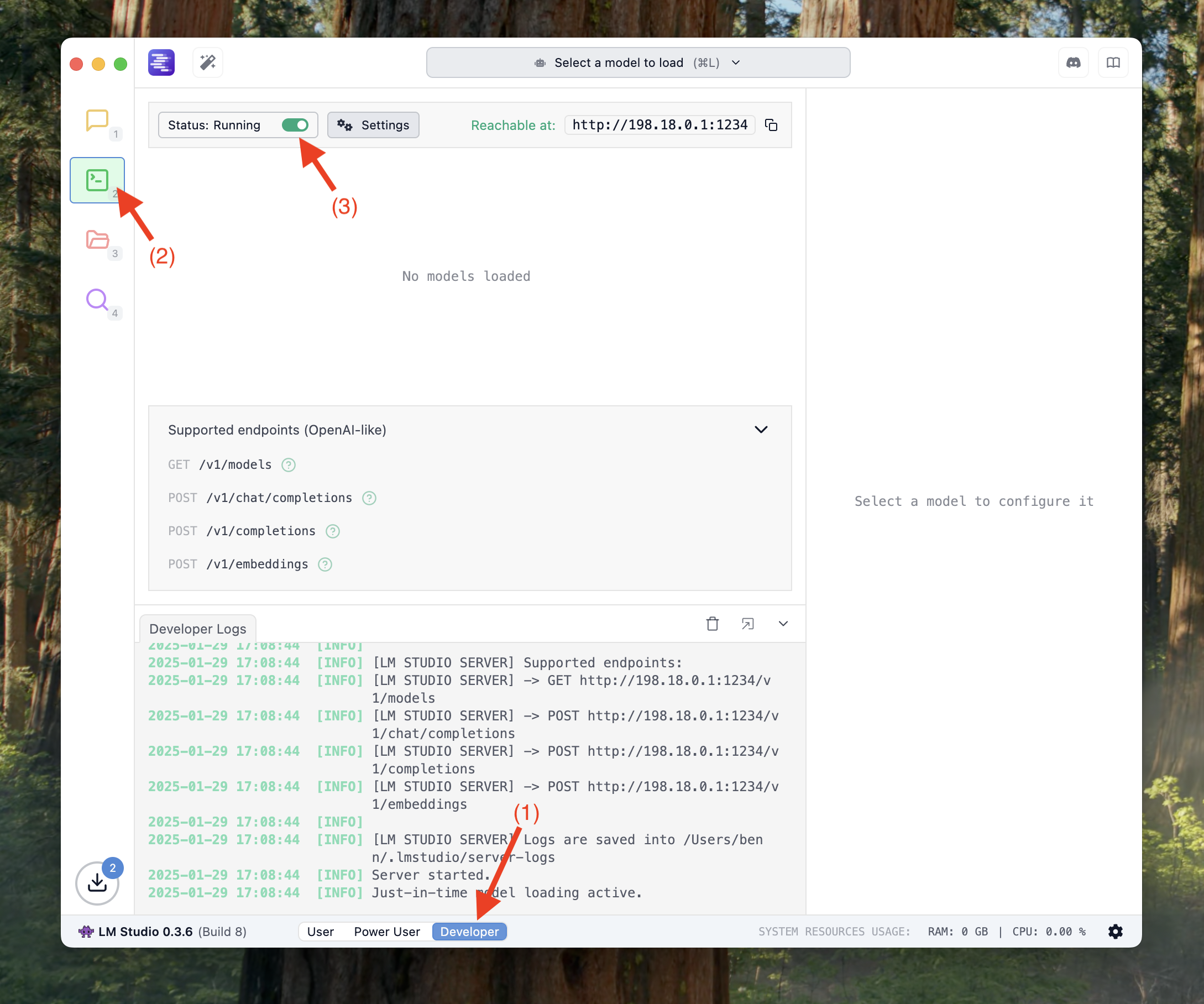
1. 开启 LM Studio 服务
请先打开 LM Studio,按顺序开启以下选项:
- 进入 Developer 模式
- 进入 Developer 面板
- 点击开关开启 Server(Status 显示为 running 即可)
如果你希望使用 Chatbox 连接当前网络下另外一台机器上运行的 LM Studio 服务,或者你希望在 Chatbox 手机应用连接到你电脑上运行的 LM Studio 服务,那么你还需要完成下面两步设置:
- 点击 Settings
- 开启 Enable CORS
- 开启 Serve on Local Network
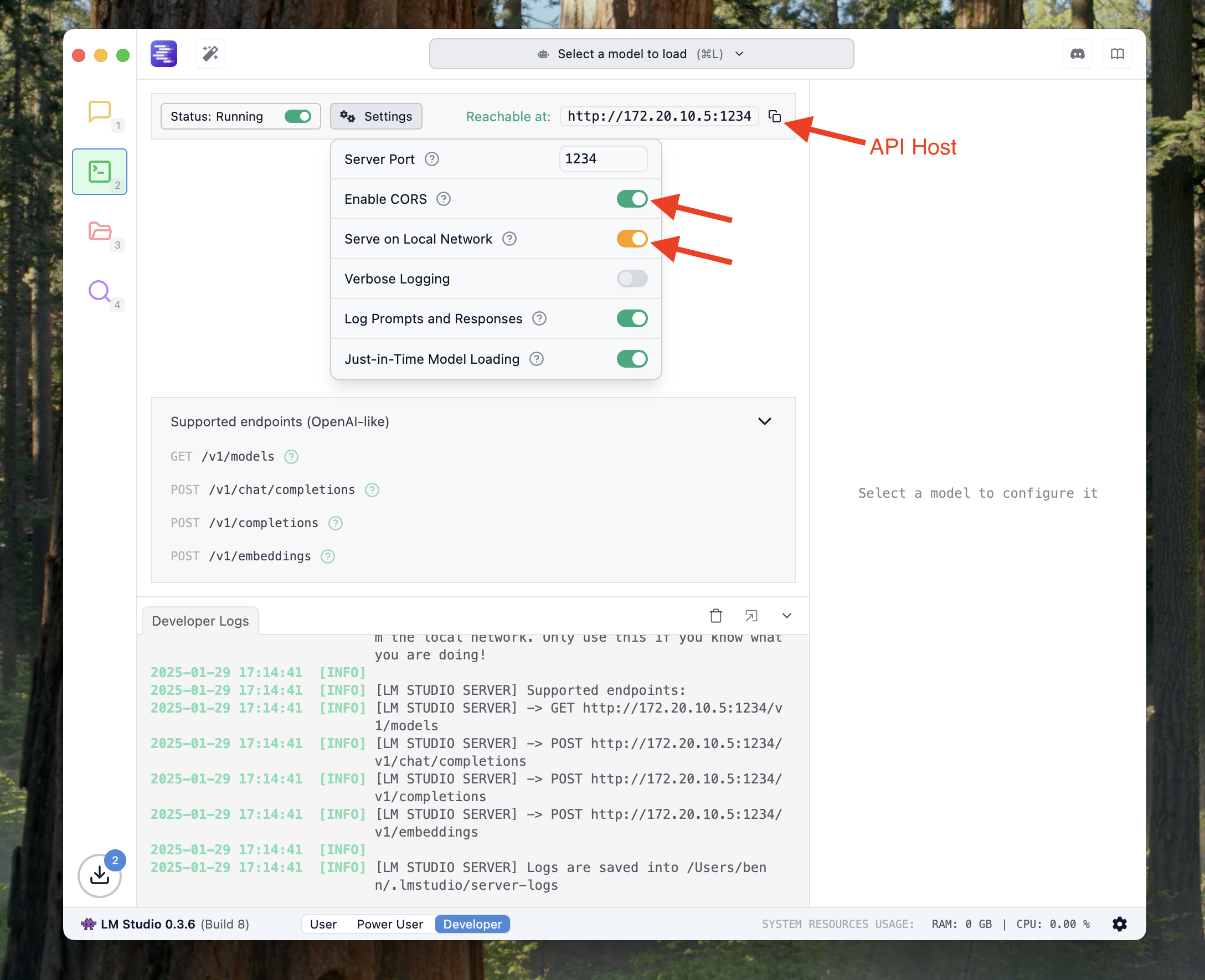
最后请复制 LM Studio 中显示的 API主机 地址。
在 Chatbox 中配置
步骤 1:打开 Chatbox 设置
- 打开 Chatbox 应用
- 点击左下角的「设置」入口
- 选择「模型提供方」
步骤 2:添加 LM Studio
- 点击「添加 」
- 搜索「LM Studio」
- 配置以下信息:
- API主机:
http://localhost:1234/v1 - API密钥:留空或填写任意字符(如
lm-studio)
- API主机:
步骤 3:选择模型
- 模型名称可以填写
default或实际模型名称 - 保存设置
- 开始对话
远程连接配置(可选)
如果你希望 Chatbox 手机 App 连接电脑上的 LM Studio,或者希望同一局域网内的另一台设备连接这台电脑上的 LM Studio,需要在 LM Studio 中额外开启局域网访问。
安全警告: 开启局域网访问后,LM Studio 服务会暴露在当前网络中。LM Studio 默认没有身份验证。请仅在受信任的局域网中使用,切勿将端口
1234暴露到公网。建议使用 VPN 或 SSH 隧道进行远程访问。
步骤1:在 LM Studio 的 Developer 面板中
开启 Enable CORS 和 Serve on Local Network
步骤 2:开放防火墙
确保端口 1234 在防火墙中开放(参考 Ollama 指南中的防火墙配置)
步骤 3:连接
在其他设备的 Chatbox 中:
- API主机:
http://你的电脑IP:1234/v1
推荐模型
| 模型 | 大小 | 内存需求 | 特点 |
|---|---|---|---|
| Llama 3.2 3B Q4 | ~2GB | 4GB+ | 速度快,适合入门 |
| Llama 3.2 8B Q4 | ~5GB | 8GB+ | 均衡之选 |
| Qwen 2.5 7B Q4 | ~4GB | 8GB+ | 中文能力出色 |
| Mistral 7B Q4 | ~4GB | 8GB+ | 推理能力强 |
常见问题
模型加载失败
可能原因:
- 内存不足
- 模型文件损坏
解决方法:
- 尝试使用更小的模型或更低的量化版本
- 重新下载模型
服务器无法启动
解决方法:
- 确保模型已加载
- 检查端口是否被占用
- 尝试更换端口
Chatbox 无法连接
排查步骤:
- 确认 LM Studio 服务器正在运行
- 检查 API 地址是否正确(注意
/v1后缀) - 尝试在浏览器访问
http://localhost:1234/v1/models
响应速度慢
优化建议:
- 使用更小的模型
- 使用更高的量化版本(如 Q4 代替 Q8)
- 关闭其他占用资源的程序
使用建议
-
选择合适的量化:
- Q4_K_M 是大多数场景的最佳选择
- 如果内存充足,可以尝试 Q5 或 Q8
-
保持服务器运行: 使用 Chatbox 时,确保 LM Studio 服务器一直在运行
-
尝试不同模型: LM Studio 的模型市场有丰富的选择,可以多尝试
-
关注系统资源: 运行模型时注意内存和 CPU/GPU 使用情况